Observability is key
As companies begin their journey of the cloud, they often start with playing around with the console, launching “Proof of Concepts”, then deploying their solutions “manually”. Very soon after, they realize the operational nightmare of managing scattered resources and start leaning towards “Infrastructure as code” tools and principles. As they grow fonder of the cloud, and start following AWS guidelines and best practices, they shift into a multi account strategy with multiple accounts popping for different needs.
As they grow more and more, they’re soon faced with challenges and questions such as “What is the status of my resources?”, “Was the latest release deployed successfully in all my accounts?”, “Which deployments fail and which accounts require a particular attention?”, acknowledging the need for observability.
AWS defines observability as a set of tools, concepts, and practices that “lets you collect, correlate, aggregate, and analyze telemetry in your network, infrastructure, and applications in the cloud, hybrid, or on-premises environments so you can gain insights into the behavior, performance, and health of your system.” This will be a series of articles with the aim of creating a solution which enables the observability of CloudFormation stacks within a distributed environment.
The series will follow the principles of Agile, meaning the overall solution will be broken down into smaller stable increments, resulting in a viable stable product at the end of each article. We will therefore follow the plan below, – or at least try to. Since we are agile, we are expected to quickly shift plans and focus as new inputs come in, either from the business/market or technical discoveries-:
- Building the foundation for log collection, transformation, and observability within a single account.
- Extending the solution to multiple accounts.
- Building real-time dashboards and analytics reports on top.
- Optimizing the solution
Architecture:
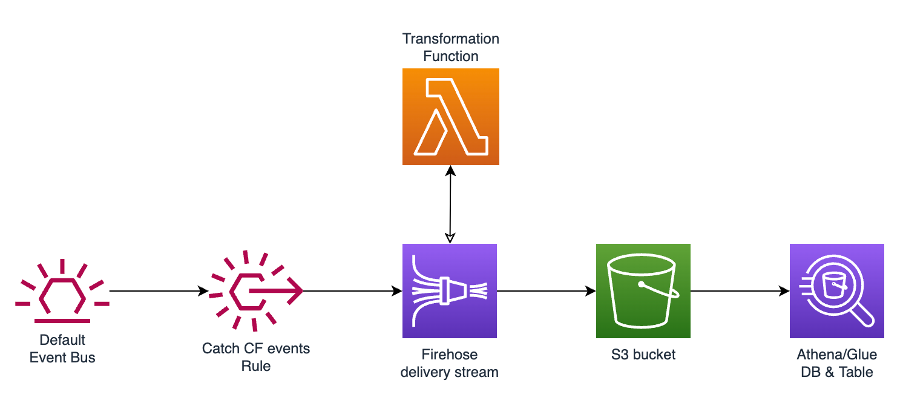
All the implementation code is available within Github: https://github.com/cloudlifter95/aws_templates/tree/main/observability_blog
The architecture is quite straightforward and leverages EventBridge for event collection, Kinesis for data ingestion and processing, S3 for storage and Athena to make sense of the collected data. The current article “observability” is scoped to CloudFormation stack resources as a first step by applying an EventBridge rule that matches CloudFormation status change events only. This design is easily modifiable to support different logs if the need arises.
Best DevOps practices dictate the use of “Infrastructure as Code (IaC)”, therefore the architecture above will be packaged into a CloudFormation template, that is going to be instantiated as CloudFormation stack. As a reminder, CloudFormation is an AWS native tool for “IaC” enabling physical resources and configurations to be instantiated from code.
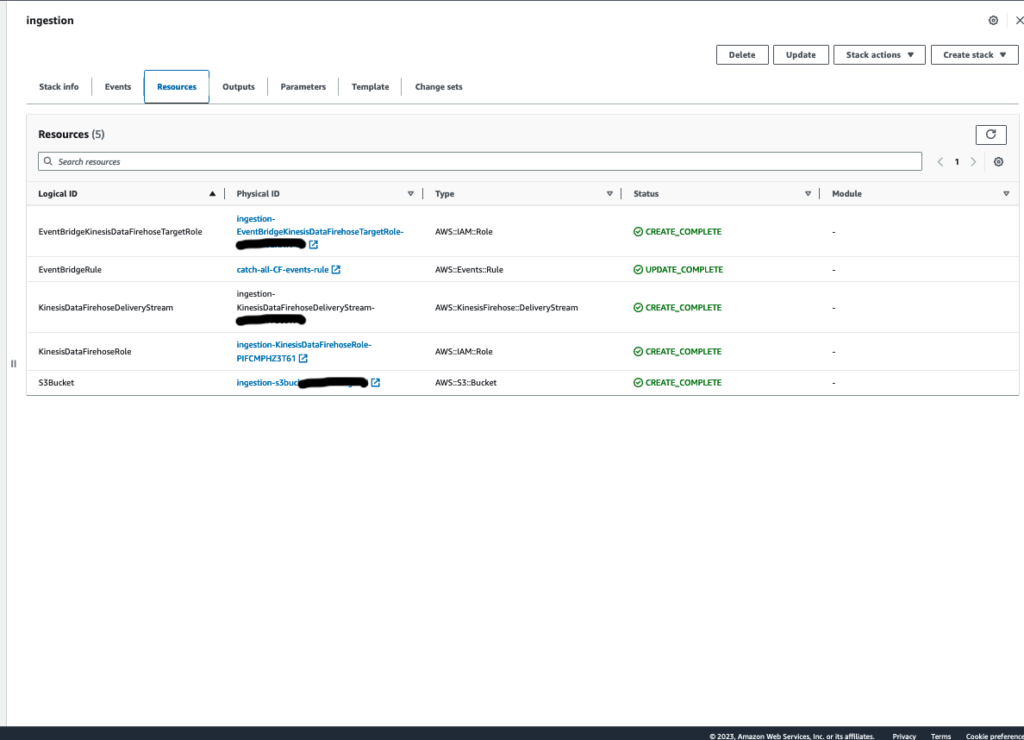
Event bridge rule that matches CF status change events:
{
“detail-type”: [“CloudFormation Stack Status Change”],
“source”: [“aws.cloudformation”]
}
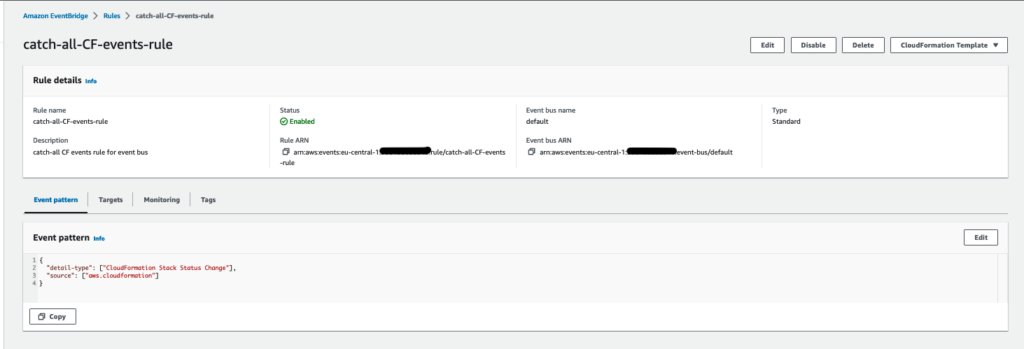
As event logs flow through event bridge, those that match our pattern are sent to the target we defined, eg: Kinesis Firehose, which is configured to process them and persist them in S3.
The screenshot below show Kinesis metrics as logs are flowing through, processed and sent to S3.
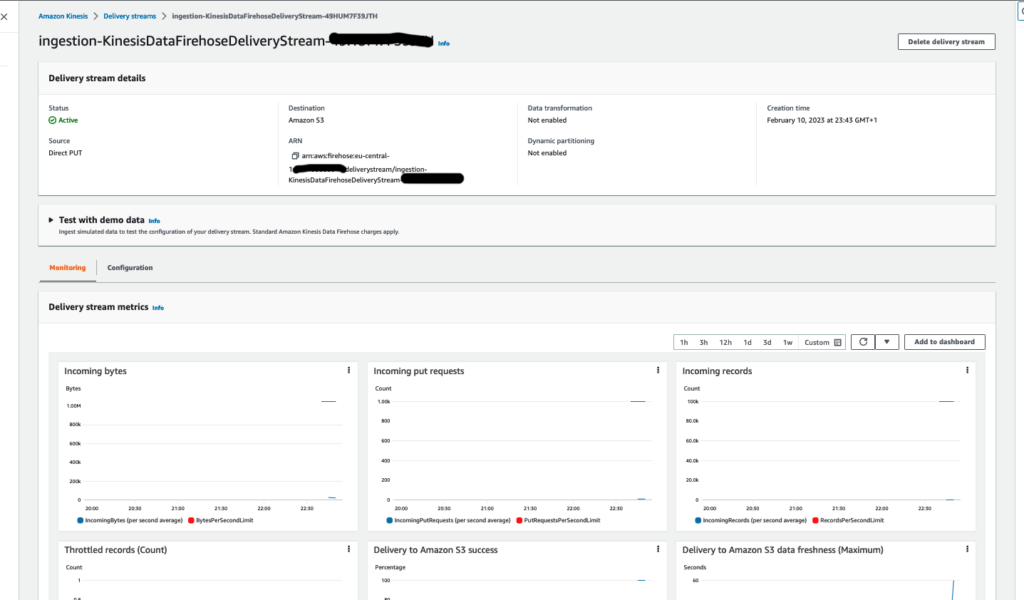
The processing we applied is basic and extracts the stack name and stack status as their own key of the log dictionary. Here, we used Lambda, but for such simple cases, Glue could also be an option. We will discuss briefly on the optimization chapter the poor and cons of using Glue.

Once the logs reach s3, Athena has data to parse on the go. From there you can run interesting queries to “observe” your environment. You can, for example, know in real-time the state of all your stacks and the account and region they are deployed in, or get a timeline of a particular stack.
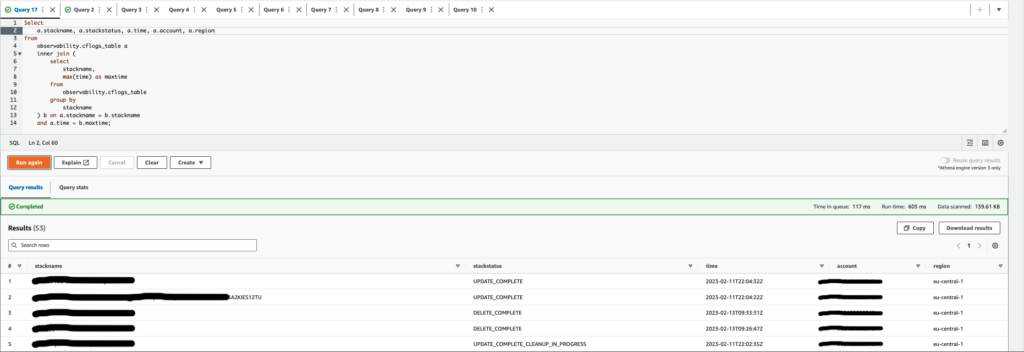
Conclusion:
We have just demonstrated how we could enable real-time observability of Cloudformation stacks status using event bridge. Now I’m sure many things could have been done better or differently, depending on the tradeoffs we could be willing to take. In fact if we follow agile practices we would call this an MVP or V0, and then, as more requirements come in, or more feedback is gathered, we will develop another version v1, and a version v2, …
Potential improvements for future versions could include but not limit to :
- Use crawlers.
- Partitioning of table -> search speed benefits.